SEKA
Spectral Attention Steering: Highlighting Prompts Without Breaking Flash Attention
The Problem
Steering Large Language Models (LLMs) to focus on specific parts of a prompt is critical for reliability. However, existing highlighting methods are architecturally flawed. They rely on **post-hoc matrix editing**, creating a computational bottleneck that breaks compatibility with modern IO-aware optimisations like Flash Attention.
We introduce **Spectral Editing Key Amplification (SEKA)**. Instead of hacking the attention matrix, SEKA intervenes upstream. We use spectral decomposition to learn universal 'relevance subspaces' and edit the key embeddings directly before attention is computed. This makes SEKA **training-free**, **interpretable**, and **fully compatible with Flash Attention**. We further introduce AdaSEKA, a query-adaptive variant that dynamically routes prompts to expert subspaces for precision steering.
Methodology
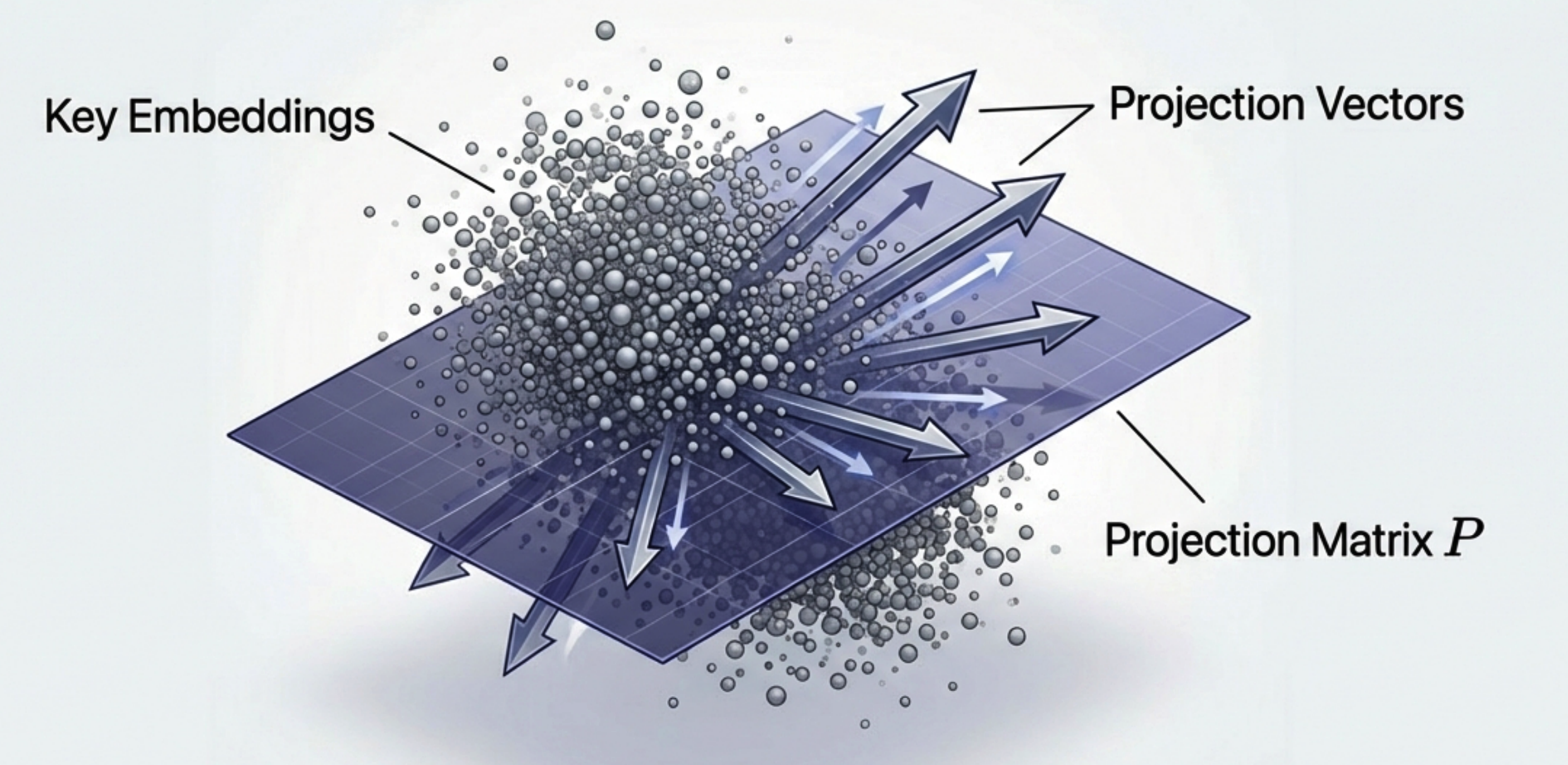
We learn a projection matrix $P$ via SVD on contrastive key embeddings. This captures the 'direction' of relevance without retraining the model.
At inference, we inject the learned projection into the key embeddings. The transformation is geometrically interpretable: $k' = k + gPk$. This selectively amplifies features aligned with the relevance subspace, forcing the attention mechanism to prioritise highlighted tokens naturally.
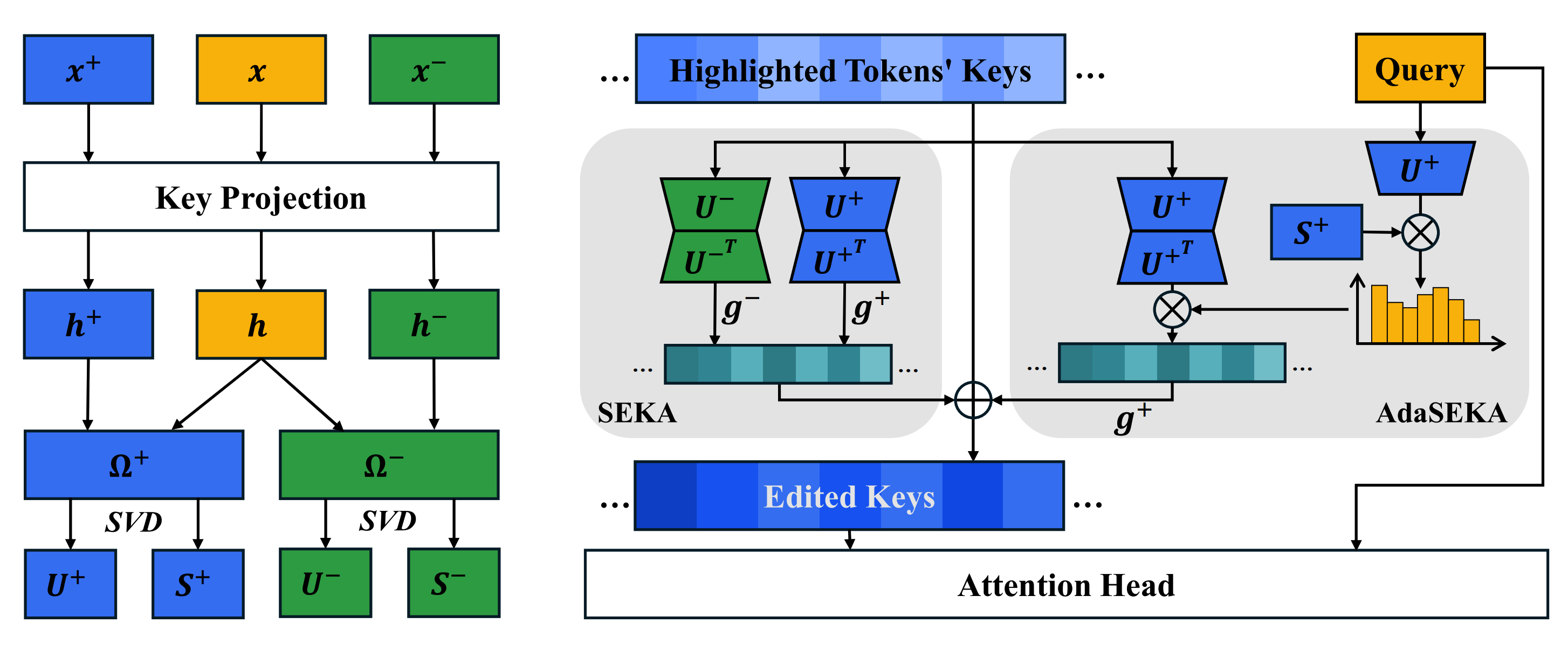
AdaSEKA employs a training-free routing mechanism. It assesses the semantic intent of the query and dynamically blends multiple expert subspaces to create a bespoke steering operator on the fly.
SOTA Performance

SEKA and AdaSEKA consistently outperform strong baselines (PASTA, SPA) on knowledge conflict (CounterFact), occupation extraction (Bias in Bios), and instruction following tasks.
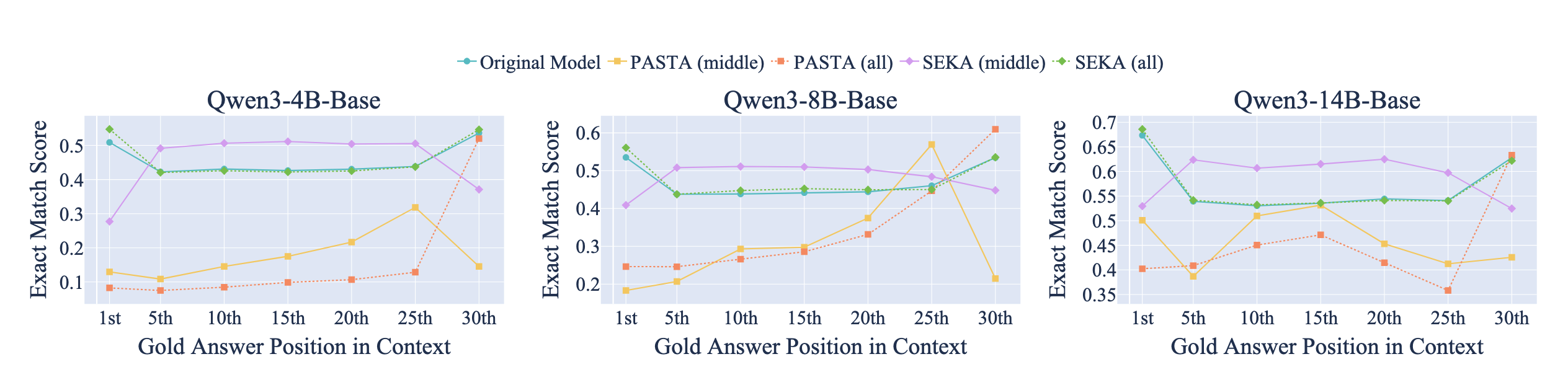
Crucially, SEKA inverts the 'Lost-in-the-Middle' phenomenon. By steering attention to the middle of long contexts, we transform the typical performance trough into a peak, enabling precise retrieval from any position.
Efficiency Analysis
The architectural advantage of SEKA is absolute. By operating on keys rather than the attention matrix, we eliminate the IO bottleneck.
SEKA adds only $\approx 0.03s$ latency per sample, whereas PASTA incurs over 1 second of delay and doubles memory usage. SEKA is the only viable solution for production-grade, long-context steering.
BibTeX
@inproceedings{li2026seka,
title={Spectral Attention Steering for Prompt Highlighting},
author={Li, Weixian Waylon and Niu, Yuchen and Yang, Yongxin and Li, Keshuang and Ma, Tiejun and Cohen, Shay B.},
booktitle={International Conference on Learning Representations (ICLR)},
year={2026},
url={https://openreview.net/forum?id=XfLvGIFmAN}
}